AI is a revolution on the horizon. And the horizon just got a few inches closer.
Sam Guinther and Cameron Auler’s Capstone pushed the boundaries of the tech field. By combining machine learning with cybersecurity, they created something innovative and effective: an AI that detects threats on a network.
Guinther and Auler were nearly fresh to machine learning as they stared this final project down. Yet it didn’t stop them from innovating; if anything, the newness of it all further pushed them forward.
“You know, it’s your Capstone project, it’s your senior year, are you really going to skimp out and do something just to get it done? I was lucky enough to have a great partner who spurred me along and we supported each other and pushed through.”
During our interview, Guinther grinned ear to ear as he recounted the steps of their project, describing their many triumphs.
“Like this is way out of our league… and we decided to just jump on it and just Google for days.”
Seeing how proud he was, I knew the project was as tough as it was rewarding.
“What we decided to do was focus on a networking approach and use a strict machine learning model approach to it.”
What does that mean? Well, it means it’s exposition time.
“AI” is used as an umbrella term, but there’s more to “AI” than AI. There are actually three types: machine learning, deep learning, and artificial intelligence itself. Guinther and Auler strictly used machine learning, as it offered features that best served their goal: making a machine evolve to detect malicious, malignant stuff on a network.
But before they could give the machine a college education, they had to find effective data to teach it with… which turned out to be the hardest part.
It took them a month and a half to find the actual data sets… which Guinther found on page twenty of Google. Just plain unlucky.
“So we just trusted and downloaded, you know, random zip files online from shady-looking websites. But it turned out to be great and our approach was using machine learning algorithms in a simple model built function in Python.”
The problems didn’t end there. Once they had all the shady data they could want, there was the not-so-small issue of making it machine-readable—another huge learning curve.
Guinther didn’t speak much about this, but machines learn a lot like us. Within machine learning, there are supervised and unsupervised learning. Supervised also has a cousin called reinforcement learning. But all you need to know for the story is that supervised learning trains a machine to reach a certain outcome about the data.
Supervised machines are trained to understand patterns in data, before being tested to make sure they understand that data. In a classroom, professors (generally) plan out what to teach every class. This involves progressing students through their studies until they know enough to take and pass a test. (Although at Champlain, those “tests” have a lot more real-world applications.) AI developers teach machines similarly.
Creating a curriculum for humans is hard enough. Imagine creating a lesson plan for a machine that you can only talk to through code, if at all. It’s crazy stuff in the best way possible.
“We would take the data and you’d essentially have to encode it into a numerical format. Which was kind of hard to wrap our heads around because you know, it’s different flags from a PCAP file, which is just like network traffic.“
In this project, the flags were key data and metadata values in the PCAP (Packet Capture) files. Think things like the total data flow on the computer, timestamps of all data packets, and key points in the computer’s website connection journey. (For that last one, think source IP, destination IP, and ports.)
Ideally, the machine would notice suspect stuff in the network traffic and sound the DDoS alarm. If it offered a high percentage, it’d mean a high chance of malicious activity.
The goal was clear. How to get there was… a lot less clear. But the duo had some ideas.
“What we ultimately decided on was [using] two different supervised machine learning models. The first one was Random Forest, Random Forest Algorithm, a decision tree algorithm that finds outliers in common, you know, data patterns and stuff.”
There’s something to be said about how they did this. Random Forest Algorithm (RFA) as a concept has been around since ‘95, and it’s gotten popular with studiers of machine learning.
But how does it work? How does machine learning work?
The tech field as a whole is intimidated by AI. After all, it’s still emerging, a potential revolution in the works. But Guinther and Auler aren’t the type to run from a little challenge.
“There’s so many resources out there, so many libraries that streamline everything. So I just realized this stuff isn’t out of my graph… with the stuff I learned, you know, it went hand in hand with it… I had the foundational support to jump on this project and just learn something out of my league.”
When you ask an open-ended question like “What’s the percentage chance that Lake Champlain freezes over this winter,” there’s a remarkable number of paths that conversation could take. You could comment on the record-high temperatures across the country or the recent floods in Vermont. A decision tree forms just from a question like “Will it be cold enough?”
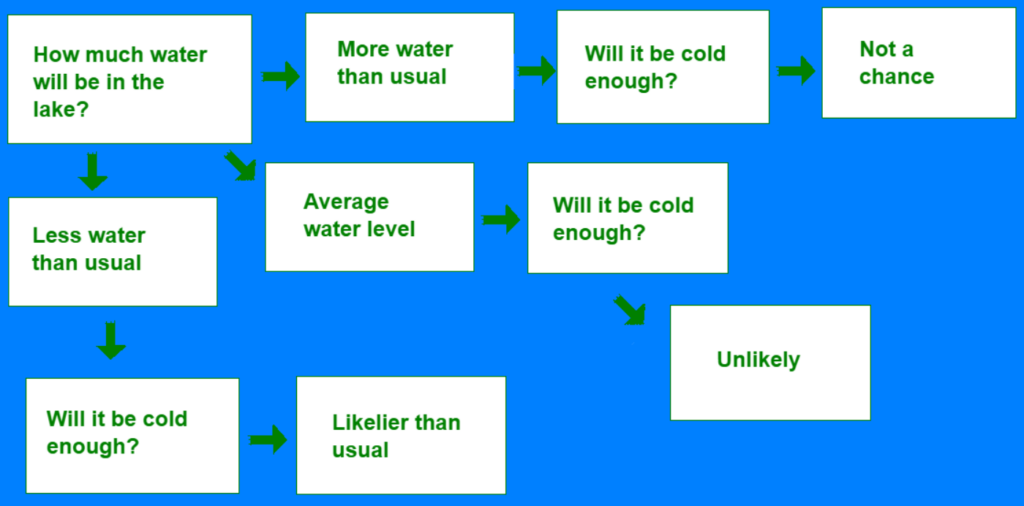
Imagine if this decision tree flowchart that took me thirty minutes to make had hundreds more questions. That’s how Guinther and Auler’s project checks if flagged data is secure. Only, instead of interrogating search engines about the weather, their machine asks all sorts of cybersecurity questions.
Of course, in a diagram hundreds of questions big, you can expect some mistakes—even with machines’ perfection.
If you know nothing about the history of Lake Champlain on ice, you’d assume freezing the lake could be easy. This is called bias.
But look at the ice data, and you realize how unlikely it’s become. The lake last froze in March 2019. The last time it froze in January was in 2004. Looking at the 200 years of data trains you to think big lakes can’t freeze over anymore. So when you’re asked if a different lake is likely to freeze, you’re inclined to say “no.” They call this variance.
Less data equals more bias, but more data equals more variance. (There’s even a Wikipedia article about this problem.) The goal when developing learning tech is to eliminate error, but this dilemma makes complete correctness a fever dream.
RFA remedies this issue by using multiple decision trees. Without giving the ten-page explanation, these multiple trees learn unique perspectives on the question. Once they reach their answers, they either average out their findings or run a majority vote on binary (yes or no) questions.
At some point in their development, they realized Random Forest wasn’t enough. RFA detected potential DDoS attacks, but it couldn’t do everything. They needed to add a second machine learning algorithm, and Isolation Forest fit the bill.
Isolation Forest Algorithm (IFA) does the same core decision tree stuff, just with different priorities. It runs off the principle that it takes fewer questions to find an outlier than it does a normal data point. By doing so, it finds anomalies faster. (For a more complex explanation that won’t fit in a normal-length article, check yet another Wikipedia page.)
The machine uses IFA to detect outlier IPs on a network. It uses RFA to detect DDoS attacks. And Python is the code that ties it together, the foundation of the whole house.
Trio-ing RFA, IFA, and Python let the machine check for questionable traffic on a computer’s network—and do so reliably.
“So our first approach… was a simple outline IP detection software… where we would send in DHCP network traffic files… then it would just pick out the outlier IPs. [This] wasn’t necessarily really over the top, it would just find ideas that weren’t commonly there and kind of flag them and say, ‘hey, this one might be, you know, malignant, might be something up with this one.’ That’s what really got our foot in the door with it. And we got it working.“
For the next month, Guinther and Auler devoted several hours every day to researching, studying, coding, testing. See, when you plug everything into the program they developed in, it straight tells you it either works or doesn’t work, with no hint as to why it doesn’t work… or why it does. The machine learning libraries in Python have a heavier learning curve than even the usual steep coding curve.
“You just have to keep changing little things, little things, little things, and then eventually [the program] will just pop out, and ‘Hey, accurate guess!’ And then we would have to go through and guess why it was an accurate guess.”
Their code only came out to around 250 lines, but that conciseness means better code. Word choice matters more in a poem than in a twenty-page essay. Guinther and Auler had to edit those 250 lines to perfection and understand what it all meant. And the pair did all this while acting as independently as possible.
“[Devin Payton,] our Capstone professor was awesome too. He gave us everything we needed. He was great, he helped us so much. But again, with that, the responsibility of doing it yourself. We tried not to lean on him as a crutch whatsoever. You know, we were seniors and we wanted to take it seriously. I think that the reason why I was so successful was because it was put on us.”
Guinther also says his former Leahy Center internship helped him succeed.
“Honestly, I’d say a lot of the stuff from Cyber Range kind of went hand in hand with our Capstone. Which was great, you know?”
As tough as this project was, Guinther sounded nostalgic as he described their work months ago.
“It was interesting to manage ourselves and use our team dynamics to push each other to just keep learning, and ultimately provide a product.”
Every day, Guinther and Auler studied. One of those days, they gathered data from a company and plugged it into the machine. The duo likely expected another failure. But it worked. It worked!
“[The company] provided entire day-long network files of an actual DDoS attack on their network. And we ran with that and we got it up to like 98% accurate predictions in our testing environment,” Guinther said, smiling. “And I don’t know, just seeing that 98 pop up on the screen after like maybe a month of just sitting there picking apart the same 100 lines of code for a couple hours a day, it was just such a boost. Such a push forward to keep going.”
“Like, you didn’t think you could do it at first, but because you kept trying, eventually you realized you could,” I said.
“Yeah, man! Classic perseverance story!” Guinther said, smiling ear to ear.
He’s working with Auler again, developing an app for language learning. The project’s very early in development, but judging from their previous success, the pair will make it work—no matter what it takes.
Stay up to date with Twitter, Instagram, Facebook, and LinkedIn so you always know what we’re up to!

By Briar Gagne ’26, Professional Writing
Briar Gagne specializes in technical writing and copywriting, with a strong focus in cybersecurity topics.
Sources:
Image by rawpixel.com on Freepik
Techopedia’s Definition of “Flag”
PCAP: Packet Capture, what it is, and what you need to know
Record temps continue on land and in the water for 2023
VT Flood Response & Recovery Fund 2023
200 Years of Lake Champlain Ice Data – Climate Change in Action
https://developers.google.com/machine-learning/crash-course/training-and-test-sets/splitting-data
https://www.obviously.ai/post/machine-learning-vs-artificial-intelligence-vs-deep-learning-whats-the-difference
https://www.simplilearn.com/tutorials/machine-learning-tutorial/bias-and-variance